Le sildénafil présent dans Kamagra exerce une inhibition réversible de la PDE5, modulant la cascade GMPc et favorisant une vasodilatation localisée. L’absorption digestive varie selon la forme utilisée, comprimés classiques ou gels oraux. La distribution tissulaire est large et la liaison protéique élevée, avoisinant 96 %. La métabolisation hépatique génère un métabolite actif contribuant à l’effet pharmacologique global. La demi-vie reste courte, avec disparition plasmatique en quelques heures. Les interactions significatives concernent surtout les nitrés organiques et inhibiteurs puissants du CYP3A4. Dans les publications techniques, kamagra en ligne est souvent cité dans le cadre d’analyses comparatives portant sur les différences de formulations et de cinétique d’absorption.
Microsoft word - eacl2012_leijten_macke_et al_definitive.docx
From character to word level: Enabling the linguistic analyses of Inputlog process data Mariëlle Leijten Lieve Macken
LT3, Language and Translation Technology
Team, University College Ghent and Ghent
Veronique Hoste Eric Van Horenbeeck
LT3, Language and Translation Technology
Team, University College Ghent and Ghent
Luuk Van Waes 1 Introduction Abstract
Keystroke logging is a popular method in writing
Keystroke logging tools are widely used in writing
research (Sullivan & Lindgren, 2006) to study the
process research. These applications are designed
underlying cognitive processes (Berninger, 2012).
to capture each character and mouse movement as
Various keystroke logging programs have been
isolated events as an indicator of cognitive processes. The current research project explores
developed, each with a different focus1. The programs
the possibilities of aggregating the logged process
differ in the events that are logged (keyboard and/or
data from the letter level (keystroke) to the word
mouse, speech recognition), in the environment that is
level by merging them with existing lexica and
logged (a program-specific text editor, MS Word or
using NLP tools. Linking writing process data to
all Windows-based applications), in their combination
lexica and using NLP tools enables researchers to
with other logging tools (e.g. eye tracking and
analyze the data on a higher, more complex level.
usability tools like Morae) and the analytic detail of
In this project the output data of Inputlog are
the output files. Examples of keystroke logging tools
segmented on the sentence level and then
tokenized. However, by definition writing process
Scriptlog: Text editor, Eyetracking (Strömqvist,
grammatical text. Coping with this problem was
Holmqvist, Johansson, Karlsson, & Wengelin,
one of the main challenges in the current project.
Therefore, a parser has been developed that
Inputlog: Windows environment, speech
extracts three types of data from the S-notation:
recognition (Leijten & Van Waes, 2006),
word-level revisions, deleted fragments, and the
Translog: Text editor, integration of dictionaries
final writing product. The within-word typing
(Jakobsen, 2006) (Wengelin et al., 2009).
errors are identified and excluded from further
analyses. At this stage the Inputlog process data are enriched with the following linguistic
information: part-of-speech tags, lemmas, chunks,
A detailed overview of available keystroke logging
syllable boundaries and word frequencies.
programs can be found on http://www.writingpro.eu/ logging_programs.php.
Keystroke loggers' data output is mainly based on
The remainder of this paper is structured as follows.
capturing each character and mouse movement as Section 2 describes the output of Inputlog, and section isolated events. In the current research project 2 we
3 describes an intermediate level of analysis. Section
explore the possibilities of aggregating the logged 4 describes the flow of the linguistic analyses and the process data from the letter level (keystroke) to the
various linguistic annotations. Section 5 wraps up
word level by merging them with existing lexica and
with some concluding remarks and suggestions for
Linking writing process data to lexica and using NLP tools enables us to analyze the data on a higher, more
2 Inputlog
complex level. By doing so we would like to stimulate interdisciplinary research, and relate findings in the
Inputlog is a word-processor independent keystroke
domain of writing research to other domains (e.g.,
logging program that not only registers keystrokes,
Pragmatics, CALL, Translation studies, Psycho-
mouse movements, clicks and pauses in MS Word,
but also in any other Windows-based software
We argue that the enriched process data combined
with temporal information (time stamps, action times
Keystroke logging programs store the complete
and pauses) will further facilitate the analysis of the
sequence of keyboard and/or mouse events in
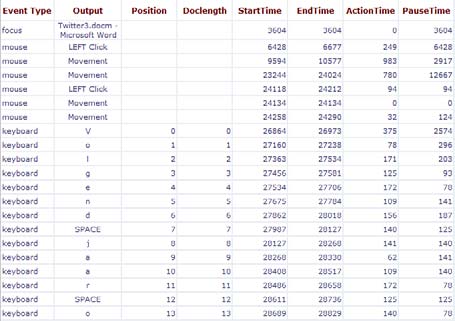
logged data and address innovative research chronological order. Figure 1 represents "Volgend questions. For instance, Is there a developmental shift
jaar (Next Year)" at the character and mouse action
in the pausing behaviors of writers related to word classes, e.g., before adjectives as opposed to before
The keyboard strokes, mouse movements and mouse
nouns (cf. cognitive development in language clicks are represented in a readable output for each production)? Do translation segments correspond to
action (e.g., 'SPACE' refers to the spacebar, LEFT
linguistic units (e.g., comparing speech recognition
Click is a left mouse click, and 'Movement' is a
and keyboarding)? Which linguistic shifts synthesized representation of a continuous mouse
characterize substitutions as a sub type of revisions
movement). Additionally, timestamps indicate when
(e.g., linguistic categories, frequency)?
keys are pressed and released, and when mouse
movements are made. For each keystroke in MSWord
A more elaborate example of a research question in
the position of the character in the document is
which the linguistic information has added value is: Is
represented as well as the total length of the document
the text prodcution of causal markers more cognitive
at that specific moment. This enables researchers to
demanding than the production of temporal markers?
take the non-linearity of the writing process into
In reading research, evidence is found that it takes
account, which is the result of the execution of
readers longer to process sentences or paragraphs that
contain causal markers than temporal markers. Does
the same hold for the production of these linguistic markers? Based on the linguistic information added to the writing process data researchers are now able to easily select causal and temporal markers and compare the process data from various perspectives. (cf. step 4 - linguistic analyses).The work described in this paper is based on the output of Inputlog3, but it can also be applied to the output of other keystroke logging programs. To promote more linguistically-oriented writing process research, Inputlog aggregates the logged process data from the character level (keystroke) to the word level. In a subsequent step, we use various Natural
Language Processing (NLP) tools to further annotate
Figure 1. Example of general analysis Inputlog.
the logged process data with different kinds of
linguistic information: part-of-speech tags, lemmata,
To represent the non-linearity of the writing process
chunk boundaries, syllable boundaries, and word the S-notation is used. The S-notation (Kollberg &
Severinson Eklundh, 2002) contains information
about the revision types (insertion or deletion), the
order of the revisions and the place in the text where
2 FWO-Merging writing process data with lexica -
the writing process was interrupted. The S-notation
can be automatically generated from the keystroke
logging data and has become a standard in the
representation of the non-linearity in writing to be the most stable characteristic of a keyboard user. processes.
Another example is the work by Nottbush and his
colleagues. Focusing on linguistic aspects of interkey
Figure 2 shows an example of the S-notation. The text
intervals, their research (Nottbusch, 2010; Sahel,
is taken from an experiment with master students Nottbusch, Grimm, & Weingarten, 2008) shows that Multilingual Professional Communication who were
the syllable boundaries within words have an effect on
asked to write a (Dutch) tweet about a conference
the temporal keystroke succession. Syllable
(VWEC). The S-notation show the final product and
boundaries lead to increased interkey intervals at the
In recent research Inputlog data has also been used to
ngres·[over·']1|1[met·als·thema|10]9{over}10·'Corporate·Com
analyze typing errors at this level (Van Waes &
munication{'|8}7.[.]2|2[·Wat·levert·het·op?'.|7]6·Blijf·[ons·vo
Leijten, 2010). As will be demonstrated in the next
lgen·op|5]4{op·de·hoogte·via|6}5·www.vwec2012.be.|3·
section, typing errors complicate the analysis of logging data at the word and sentence level because
the linear reconstruction is disrupted. For this purpose
a large experimental corpus based on a controled
The following conventions are used in the S-notation:
copying task was analyzed, focusing on five digraphs
with different characteristics (frequency, keyboard
distribution, left-right coordination). The results of a
{insertion}i An insertion occurring after break i
multilevel analysis show that there is no correlation
[deletion]i A deletion occurring after break i
between the frequency of a digraph and the chance
that a typing error occurs. However, typing errors
The example in Figure 2 can be read as follows:
show a limited variation: pressing the adjacent key
The writer formulates in one segment "Volgend jaar
explains more than 40 % of the errors, both for touch
organiseert VWEC een congres over '" (Next year
typists and others; the chance that a typing error is
VWEC organises a conference on '). She decides to
made is related to the characteristics of the digraph,
delete "over '" (index 1) and then adds the remainder
and the individual typing style. Moreover, the median
of her first draft "met als thema 'Corporate pausing time preceding a typing error tends to be Communication. Wat levert het op?. (themed
longer than the median interkey transitions of the
Corporate Communication. What is in it for us?.)"
intended digraph typed correctly. These results
She deletes a full stop and ends with "Blijf ons volgen
illustrate that further research should make it possible
op www.vwec2012.be." (Follow us on to identify and isolate typing errors in logged process www.vwec2012.be). The third revision is the addition
data and build an algorithm to filter them during data
of the hashtag before VWEC. Then she rephrases "ons
preparation. This would benefit parsing at a later stage
volgen op" into "op de hoogte via". She notices that
her tweet is too long (max. 140 characters) and she decides to delete the subtitle of the conference. She
4 Flow of linguistic analyses
adds the adjective "boeiend" (interesting) to conference and ends by deleting "met als thema" As explained above, writing process data gathered via
the traditional keystroke logging tools, are represented at the character level and produce non-linear data 3 Intermediate level
(containing sentence fragments, unfinished sentences/words and spelling errors). These two
At the intermediate level, Inputlog data can also be
characteristics are the main obstacles that we need to
used to analyze data at the digraph level, for instance,
cope with to analyse writing process data on a higher
to study interkey intervals (or digraph latency) in level. In this section we explain the flow of the relation to typing speed, keyboard efficiency of touch
typists and others, dyslexia and keyboard fluency, biometric verification etc. For this type of research,
Step 1 - aggregate letter to word level
logging data can be leveled up to an intermediate
Natural Language Processing tools, such as part-of-
level in which two consecutive events are treated as a
speech taggers, lemmatizers and chunkers are trained
on (completed) sentences and words. Therefore, to
use the standard NLP tools to enrich the process data
Grabowski’s research on the internal structure of with linguistic information, in a first step, words, students’ keyboard skills in different writing tasks is a
word groups and sentences are extracted from the
case in point (Grabowski, 2008). He studied whether
there are patterns of overall keyboard behavior and
whether such patterns are stable across different The S-notation was used as a basis to further segment (copying) tasks. Across tasks, typing speed turned out
the data into sentences and tokenize them. A
dedicated sentence segmenting and tokenizer module
into three types of revisions and the within-word
was developed to conduct this process. This dedicated
typing errors are excluded from further analyses.
module can cope with the specific S-notation Although the set-up of the Inputlog extension is annotations such as insertion, deletion and break largely language-independent, the NLP tools used are markers.
language-dependent. As proof-of-concept, we provide
evidence from English and Dutch (See Figure 3).
Step 2 – parsing the S-notation
As mentioned before, standard NLP tools are designed to work with clean, grammatically correct text. We thus decided to treat word-level revisions differently than higher level revisions and to distinguish deleted fragments from the final writing product. We developed a parser that extracts three types of data from the S-notation: word-level revisions, deleted fragments and the final writing product. The word-level revisions can be extracted from the S-notation by retaining all words with word-internal square or curly brackets (see excerpt 1). (1 - word level revision)
Delet[r]ion incorrect: Deletrion; correct: deletion In{s}ertion incorrect: Inertion; correct: insertion
Figure 3. Flow of the linguistic analyses.
Step 3 - enriching process data with linguistic
Conceptually, the deleted fragments can be extracted
information
from the S-notation by retaining only the words and
As standard NLP tools are trained on clean data, these
phrases that are surrounded by word-external square
tools are not suited for processing input containing
brackets (2); and the final product data can be spelling errors. Therefore, we only enrich the final
obtained by deleting everything in between square
product data and the deleted fragments with different
brackets from the S-notation. In practice, the situation
kinds of linguistic annotations. As part-of-speech
is more complicated as insertions and deletions can be
taggers typically use the surrounding local context to
determine the proper part-of-speech tag for a given
word (typically a window of two to three words
An example of the three different data types extracted
and/or tags is used), the deletions in context are
from the S-notation is presented in the excerpt below.
extracted from the S-notation to be processed by the
To facilitate the readability of the resulting data, the
part-of-speech tagger. The deleted fragments in
context consist of the whole text string without the
insertions and are only used to optimize the results of
Volgend·jaar·organiseert·{#}VWEC·een·{boeiend·}c
ongres·[over·'][met·als·thema]{over}·'Corporate·Co
mmunication{'}.[.][·Wat·levert·het·op?'.]·Blijf·[ons·v
Volgend·jaar·organiseert·{#}VWEC·een·{boeiend·}c
olgen·op]{op·de·hoogte·via|}·www.vwec2012.be.|·
ongres·[over·'][met·als·thema]{over}·'Corporate·Co
mmunication{'}.[.][·Wat·levert·het·op?'.]·Blijf·[ons·v
olgen·op]{op·de·hoogte·via|}·www.vwec2012.be.|·
Volgend·jaar·organiseert·{#}VWEC·een·{boeiend·}congres·[over·'][met·als·thema]{over}·'Corporate·Co
mmunication{'}.[.][·Wat·levert·het·op?'.]·Blijf·[ons·v
Annotations For the shallow linguistic analysis, we used the LT3
olgen·op]{op·de·hoogte·via|}·www.vwec2012.be.|·
shallow parsing tools suite consisting of:
Next year #VWEC organises an interesting a chunker (LeTsCHUNK).
conference about Corporate Communication. Follow
The LT3 tools are platform-independent and hence
In sum, the output of Inputlog data is segmented in
sentences and tokenized. The S-notation is divided
In the IOB-tagging scheme, each token belongs to one
The English PoS tagger uses the Penn Treebank tag
of the following three types: I (inside), O (outside)
set, which contains 45 distinct tags. The Dutch part-
and B (begin); the B- en I-tags are followed by the
of-speech tagger uses the CGN tag set codes (Van
chunk type, e.g. B-VP, I-VP. We adapted the IOB-
Eynde, Zavrel, & Daelemans, 2000), which is tagging scheme and added end tag (E) to explicitly characterized by a high level of granularity. Apart
mark the end of a chunk. Accuracy sores of part-of-
from the word class, the CGN tag set codes a wide
speech taggers and lemmatizers typically fluctuate
range of morpho-syntactic features as attributes to the
around 97-98%; accuracy scores of 95-96% are
word class. In total, 316 distinct tags are discerned.
After annotation, the final writing product, deleted
During lemmatization, for each orthographic token,
fragments and word-level corrections are aligned and
the base form (lemma) is generated. For verbs, the
the indices are restored. Figure 4 and 5 show how we
base form is the infinitive; for most other words, this
enriched the logged process data with different kinds
base form is the stem, i.e. the word form without
of linguistic information: lemmata, part-of-speech
inflectional affixes. The lemmatizers make use of the
predicted PoS codes to disambiguate ambiguous word
forms, e.g. Dutch "landen" can be an infinitive (base
We further added some word-level annotations on the
form "landen") or plural form of a noun (base form
final writing product and the deletions, viz. syllable
"land"). The lemmatizers were trained on the English
boundaries and word frequencies (see last two
and Dutch parts of the Celex lexical database columns in Figure 4 and 5). respectively (Baayen, Piepenbrock, & van Rijn, 1993).
The syllabification tools were trained on Celex
(http://lt3.hogent.be/en/tools/timbl-syllabification).
During text chunking syntactically related consecutive
Syllabification was approached as a classification
words are combined into non-overlapping, non-
task: a large instance base of syllabified data is
recursive chunks on the basis of a fairly superficial
presented to a classification algorithm, which
analysis. The chunks are represented by means of automatically learns from it the patterns needed to IOB-tags.
syllabify unseen data. Accuracy scores for
syllabification reside in the range of 92-95%.
Figure 4. Final writing product and word-level revisions enrich
Table 1. Example of process data and linguistic information
Frequency lists for Dutch and English were compiled
on the basis of Wikipedia pages, which were extracted
from the XML dump of the Dutch and English
Wikipedia of December 2011. We used the Wikipedia
Extractor developed by Medialab4 to extract the text
from the wiki files. The Wikipedia text files were
further tokenized and enriched with part-of-speech B (begin)
tags and lemmata. The Wikipedia frequency lists can
thus group different word forms belonging to one lemma.
The current version of the Dutch frequency list has
been compiled on the basis of nearly 100 million In this example the mean pausing time before tokens coming from 395,673 wikipedia pages, which
adjectives is twice as long as before nouns. The
is almost half of the Dutch wikipedia dump of pausing time after such a segment shows the opposite December 2011.
proportion. Also pauses in the beginning of chunks
are more than twice as long as in the middle of a
Frequencies are presented as absolute frequencies.
5 Future research
In this paper we presented how writing process data can be enriched with linguistic information. The annotated output facilitates the linguistic analysis of the logged data and provides a valuable basis for more linguistically-oriented writing process research.We hope that this perspective will further enrich writing process research. Additional annotations and analyses In a first phase we only focused on English and Dutch, but the method can be easily applied to other languages as well provided that the linguistic tools are available for a Windows platform. For the moment, the linguistic annotations are limited to part-of-speech tags, lemmata, chunk information, syllabification and word frequency information, but can be extended, e.g. by n-gram frequencies to capture collocations. By aggregating the logged process data from the
character level (keystroke) to the word level, general
Figure 5. Deleted fragments enriched with linguistic
statistics (e.g. total number of deleted or inserted
words, pause length before nouns preceded by an
adjective or not) can be generated easily from the
Step 4 - combining process data with linguistic output of Inputlog as well. information.
In a final step we combine the process data with the
Technical flow of Inputlog & linguistic tools
linguistic information. Based on the time information
At this point Inputlog is a standalone program which
provided by Inputlog, researchers can calculate needs to be installed on the same local machine that is various measures, eg. length of a pause within, before
used to produce the texts. This makes sense as long as
and after lemmata, part-of-speech tags, and at chunk
the heaviest part of the work is the logging of a
writing process. However, extending the scope from a
character based analysis device to a system that
As an example Table 1 shows the mean pausing time
supplements fine grained production and process
before and after the adjectives and nouns in the tweet.
information to various NLP tools is a compelling
Of course, this is a very small-scale example, but it
reason to rethink the overall architecture of the
shows the possibilities of exploring writing process
It is not feasible to install the necessary linguistic
software with its accompanying databases on every
4 http://medialab.di.unipi.it/wiki/Wikipedia_Extractor
device. By decoupling the capturing part from the
compounds: Effects of lexical frequency and
analytics a research group will have a better view on
semantic transparency. Written Language
the use of its hard- and software resources while also
allowing to solve potential copyright issues. Inputlog
Strömqvist, S., Holmqvist, K., Johansson, V.,
is now pragmatically Windows-based, but with the
Karlsson, H., & Wengelin, A. (2006). What
new architecture any tool on any OS will be capable
keystroke logging can reveal about writing.
to exchange data and results. It will be possible to add
In K. P. H. Sullivan & E. Lindgren (Eds.),
a NLP module that receives Inputlog data through a
Computer Keystroke Logging and Writing:
communication layer. A workflow procedure then
Methods and Applications (pp. 45-71).
presents the data in order to the different NLP
packages and collects the final output. Because all
Sullivan, K. P. H., & Lindgren, E. (2006). Computer
data traffic is done with xml files, cooperation
Key-Stroke Logging and Writing. Oxford:
between software with different creeds becomes
conceivable. Finally, the module has an Van Eynde, F., Zavrel, J., & Daelemans, W. (2000). administration utility handling the necessary user
Part of Speech Tagging and Lemmatisation for the Spoken Dutch Corpus. Paper presented at the Proceedings of the second
Acknowledgements
International Conference on Language Resources and Evaluation (LREC), Athens,
This study is partially funded by a research grant of
the Flanders Research Foundation (FWO 2009-2012).
Van Waes, L., & Leijten, M. (2010). The dynamics of typing errors in text production. Paper
6 References
presented at the SIG Writing 2010, 12th International Conference of the Earli Special
Baayen, R. H., R. Piepenbrock, & H. van Rijn. (1993). The
CELEX lexical database on CD-ROM. Wengelin, A., Torrance, M., Holmqvist, K., Simpson, Philadelphia, PA: Linguistic Data Consortium.
Baayen, R. H., Piepenbrock, R., & van Rijn, H.
Johansson, R. (2009). Combined eyetracking
(1993). The CELEX lexical database on CD-
and keystroke-logging methods for studying
Behavior Research Methods, 41(2), 337-351.
Berninger, V. (2012). Past, Present, and Future Contributions of Cognitive Writing Research to Cognitive Psychology: Taylor and Francis.
Grabowski, J. (2008). The internal structure of
university students’ keyboard skills. Journal of Writing Research, 1(1), 27-52.
Jakobsen, A. L. (2006). Translog: Research methods
in translation. In K. P. H. Sullivan & E. Lindgren (Eds.), Computer Keystroke Logging and Writing: Methods and Applications (pp. 95-105). Oxford: Elsevier.
Kollberg, P., & Severinson Eklundh, K. (2002).
Studying writers' revising patterns with S-notation analysis. In T. Olive & C. M. Levy (Eds.), Contemporary Tools and Techniques for Studying Writing (pp. 89-104). Dordrecht: Kluwer Academic Publishers.
Leijten, M., & Van Waes, L. (2006). Inputlog: New
Perspectives on the Logging of On-Line Writing. In K. P. H. Sullivan & E. Lindgren (Eds.), Computer Keystroke Logging and Writing: Methods and Applications (pp. 73-94). Oxford: Elsevier.
Nottbusch, G. (2010). Grammatical planning,
execution, and control in written sentence production. Reading and Writing, 23(7), 777-801.
Sahel, S., Nottbusch, G., Grimm, A., & Weingarten,
Identifying potential adverse effects using the web: a new approach to medical Adrian Benton, BAa,*, Lyle Ungar, PhDc, Shawndra Hill, PhDb, Sean Hennessy, PharmD, PhDa, Jun Mao, MD, MSCEa, Annie Chung, BAa, Charles E. Leonard, PharmDa, John H. Holmes, a University of Pennsylvania School of Medicine, Philadelphia, PA b University of Pennsylvania, The Wharton School, Philadelphia, PA c Universi
Nyheter i bestillingsutvalget pr. 3. mai 2013 Artikkelnr. Artikkelnavn Produsent Land Distrikt First Drop And The Mother Of All Harvests 2011First Drop Mothers Milk Barossa Shiraz 2011Trenel Juliénas Esprit de Marius Sangouard 2011Moulin des Vrilleres Lauverjat Sancerre Rouge 2012Dom. Gayda Figure Libre Cabernet Franc 2011Didier Montchevet Hautes Côtes de Beaune 2011Eric Tex
 Keystroke loggers' data output is mainly based on
The remainder of this paper is structured as follows.
capturing each character and mouse movement as Section 2 describes the output of Inputlog, and section isolated events. In the current research project 2 we
3 describes an intermediate level of analysis. Section
explore the possibilities of aggregating the logged 4 describes the flow of the linguistic analyses and the process data from the letter level (keystroke) to the
various linguistic annotations. Section 5 wraps up
word level by merging them with existing lexica and
with some concluding remarks and suggestions for
Linking writing process data to lexica and using NLP tools enables us to analyze the data on a higher, more
2 Inputlog
Keystroke loggers' data output is mainly based on
The remainder of this paper is structured as follows.
capturing each character and mouse movement as Section 2 describes the output of Inputlog, and section isolated events. In the current research project 2 we
3 describes an intermediate level of analysis. Section
explore the possibilities of aggregating the logged 4 describes the flow of the linguistic analyses and the process data from the letter level (keystroke) to the
various linguistic annotations. Section 5 wraps up
word level by merging them with existing lexica and
with some concluding remarks and suggestions for
Linking writing process data to lexica and using NLP tools enables us to analyze the data on a higher, more
2 Inputlog 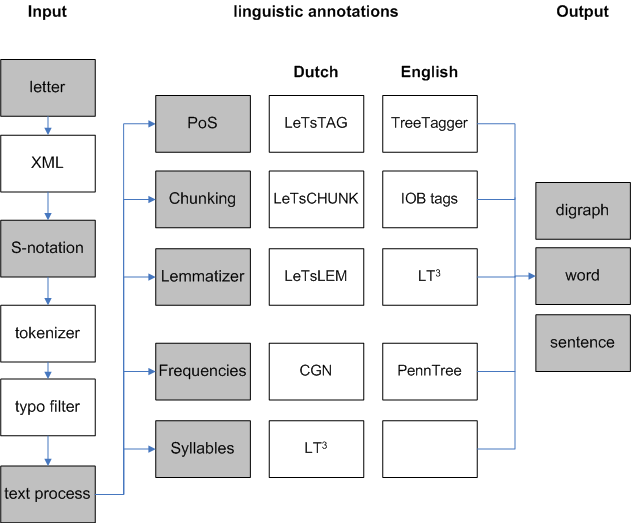 dedicated sentence segmenting and tokenizer module
into three types of revisions and the within-word
was developed to conduct this process. This dedicated
typing errors are excluded from further analyses.
module can cope with the specific S-notation Although the set-up of the Inputlog extension is annotations such as insertion, deletion and break largely language-independent, the NLP tools used are markers.
language-dependent. As proof-of-concept, we provide
evidence from English and Dutch (See Figure 3).
Step 2 – parsing the S-notation
dedicated sentence segmenting and tokenizer module
into three types of revisions and the within-word
was developed to conduct this process. This dedicated
typing errors are excluded from further analyses.
module can cope with the specific S-notation Although the set-up of the Inputlog extension is annotations such as insertion, deletion and break largely language-independent, the NLP tools used are markers.
language-dependent. As proof-of-concept, we provide
evidence from English and Dutch (See Figure 3).
Step 2 – parsing the S-notation 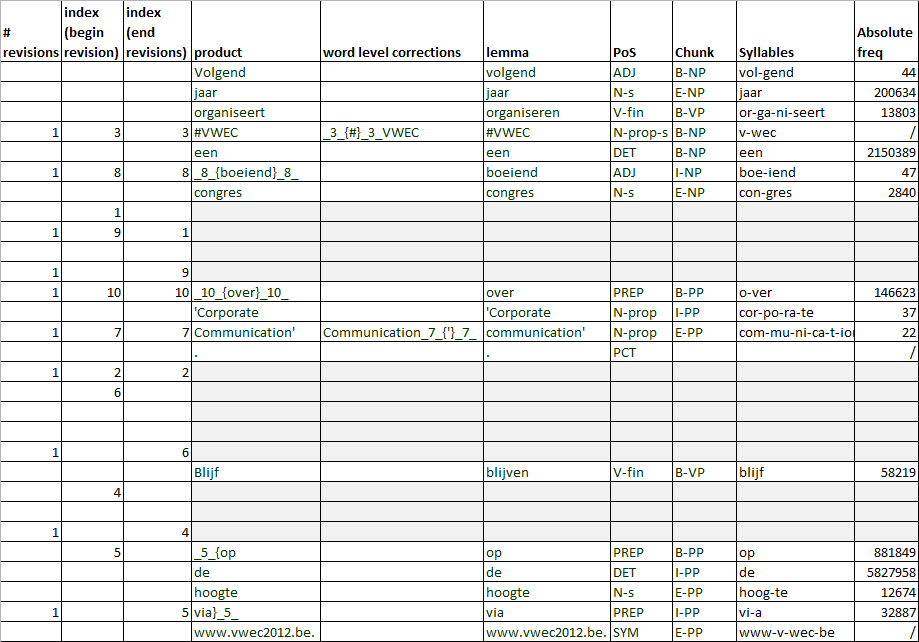 In the IOB-tagging scheme, each token belongs to one
The English PoS tagger uses the Penn Treebank tag
of the following three types: I (inside), O (outside)
set, which contains 45 distinct tags. The Dutch part-
and B (begin); the B- en I-tags are followed by the
of-speech tagger uses the CGN tag set codes (Van
chunk type, e.g. B-VP, I-VP. We adapted the IOB-
Eynde, Zavrel, & Daelemans, 2000), which is tagging scheme and added end tag (E) to explicitly characterized by a high level of granularity. Apart
mark the end of a chunk. Accuracy sores of part-of-
from the word class, the CGN tag set codes a wide
speech taggers and lemmatizers typically fluctuate
range of morpho-syntactic features as attributes to the
around 97-98%; accuracy scores of 95-96% are
word class. In total, 316 distinct tags are discerned.
After annotation, the final writing product, deleted
During lemmatization, for each orthographic token,
fragments and word-level corrections are aligned and
the base form (lemma) is generated. For verbs, the
the indices are restored. Figure 4 and 5 show how we
base form is the infinitive; for most other words, this
enriched the logged process data with different kinds
base form is the stem, i.e. the word form without
of linguistic information: lemmata, part-of-speech
inflectional affixes. The lemmatizers make use of the
predicted PoS codes to disambiguate ambiguous word
forms, e.g. Dutch "landen" can be an infinitive (base
We further added some word-level annotations on the
form "landen") or plural form of a noun (base form
final writing product and the deletions, viz. syllable
"land"). The lemmatizers were trained on the English
boundaries and word frequencies (see last two
and Dutch parts of the Celex lexical database columns in Figure 4 and 5). respectively (Baayen, Piepenbrock, & van Rijn, 1993).
The syllabification tools were trained on Celex
(http://lt3.hogent.be/en/tools/timbl-syllabification).
During text chunking syntactically related consecutive
Syllabification was approached as a classification
words are combined into non-overlapping, non-
task: a large instance base of syllabified data is
recursive chunks on the basis of a fairly superficial
presented to a classification algorithm, which
analysis. The chunks are represented by means of automatically learns from it the patterns needed to IOB-tags.
syllabify unseen data. Accuracy scores for
syllabification reside in the range of 92-95%.
Figure 4. Final writing product and word-level revisions enrich
In the IOB-tagging scheme, each token belongs to one
The English PoS tagger uses the Penn Treebank tag
of the following three types: I (inside), O (outside)
set, which contains 45 distinct tags. The Dutch part-
and B (begin); the B- en I-tags are followed by the
of-speech tagger uses the CGN tag set codes (Van
chunk type, e.g. B-VP, I-VP. We adapted the IOB-
Eynde, Zavrel, & Daelemans, 2000), which is tagging scheme and added end tag (E) to explicitly characterized by a high level of granularity. Apart
mark the end of a chunk. Accuracy sores of part-of-
from the word class, the CGN tag set codes a wide
speech taggers and lemmatizers typically fluctuate
range of morpho-syntactic features as attributes to the
around 97-98%; accuracy scores of 95-96% are
word class. In total, 316 distinct tags are discerned.
After annotation, the final writing product, deleted
During lemmatization, for each orthographic token,
fragments and word-level corrections are aligned and
the base form (lemma) is generated. For verbs, the
the indices are restored. Figure 4 and 5 show how we
base form is the infinitive; for most other words, this
enriched the logged process data with different kinds
base form is the stem, i.e. the word form without
of linguistic information: lemmata, part-of-speech
inflectional affixes. The lemmatizers make use of the
predicted PoS codes to disambiguate ambiguous word
forms, e.g. Dutch "landen" can be an infinitive (base
We further added some word-level annotations on the
form "landen") or plural form of a noun (base form
final writing product and the deletions, viz. syllable
"land"). The lemmatizers were trained on the English
boundaries and word frequencies (see last two
and Dutch parts of the Celex lexical database columns in Figure 4 and 5). respectively (Baayen, Piepenbrock, & van Rijn, 1993).
The syllabification tools were trained on Celex
(http://lt3.hogent.be/en/tools/timbl-syllabification).
During text chunking syntactically related consecutive
Syllabification was approached as a classification
words are combined into non-overlapping, non-
task: a large instance base of syllabified data is
recursive chunks on the basis of a fairly superficial
presented to a classification algorithm, which
analysis. The chunks are represented by means of automatically learns from it the patterns needed to IOB-tags.
syllabify unseen data. Accuracy scores for
syllabification reside in the range of 92-95%.
Figure 4. Final writing product and word-level revisions enrich
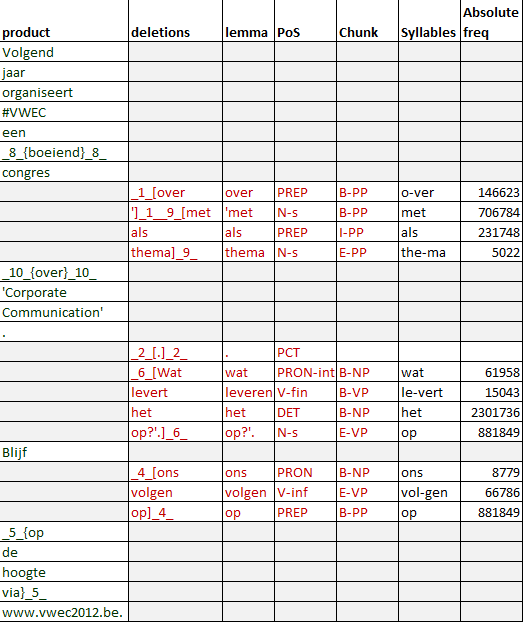 Table 1. Example of process data and linguistic information
Frequency lists for Dutch and English were compiled
on the basis of Wikipedia pages, which were extracted
from the XML dump of the Dutch and English
Wikipedia of December 2011. We used the Wikipedia
Extractor developed by Medialab4 to extract the text
from the wiki files. The Wikipedia text files were
further tokenized and enriched with part-of-speech B (begin)
tags and lemmata. The Wikipedia frequency lists can
thus group different word forms belonging to one lemma.
The current version of the Dutch frequency list has
been compiled on the basis of nearly 100 million In this example the mean pausing time before tokens coming from 395,673 wikipedia pages, which
adjectives is twice as long as before nouns. The
is almost half of the Dutch wikipedia dump of pausing time after such a segment shows the opposite December 2011.
proportion. Also pauses in the beginning of chunks
are more than twice as long as in the middle of a
Frequencies are presented as absolute frequencies.
5 Future research
Table 1. Example of process data and linguistic information
Frequency lists for Dutch and English were compiled
on the basis of Wikipedia pages, which were extracted
from the XML dump of the Dutch and English
Wikipedia of December 2011. We used the Wikipedia
Extractor developed by Medialab4 to extract the text
from the wiki files. The Wikipedia text files were
further tokenized and enriched with part-of-speech B (begin)
tags and lemmata. The Wikipedia frequency lists can
thus group different word forms belonging to one lemma.
The current version of the Dutch frequency list has
been compiled on the basis of nearly 100 million In this example the mean pausing time before tokens coming from 395,673 wikipedia pages, which
adjectives is twice as long as before nouns. The
is almost half of the Dutch wikipedia dump of pausing time after such a segment shows the opposite December 2011.
proportion. Also pauses in the beginning of chunks
are more than twice as long as in the middle of a
Frequencies are presented as absolute frequencies.
5 Future research