Le sildénafil présent dans Kamagra exerce une inhibition réversible de la PDE5, modulant la cascade GMPc et favorisant une vasodilatation localisée. L’absorption digestive varie selon la forme utilisée, comprimés classiques ou gels oraux. La distribution tissulaire est large et la liaison protéique élevée, avoisinant 96 %. La métabolisation hépatique génère un métabolite actif contribuant à l’effet pharmacologique global. La demi-vie reste courte, avec disparition plasmatique en quelques heures. Les interactions significatives concernent surtout les nitrés organiques et inhibiteurs puissants du CYP3A4. Dans les publications techniques, kamagra en ligne est souvent cité dans le cadre d’analyses comparatives portant sur les différences de formulations et de cinétique d’absorption.
Microsoft word - 069_p26_shepherd_formatted.doc
Evaluation of Health Information on the Web
Sathi Marath1, Michael Shepherd1, Carolyn Watters1,
2 {sander.van.zanten, jack.duffy}@dal.ca
Abstract. There is a growing number of websites containing patient or consumer health information. The assumption is that patients should be able to become knowledgeable about their health conditions and become more involved in the management of their own health, but there are concerns about the validity of the information to be found on the Web. The goal of this research is to develop a system that evaluates websites containing educational information about Inflammatory Bowel Disease (IBD) to determine their quality and appropriateness for consumers. A small number of websites on IBD were evaluated manually by experts in the field. A number of different approaches based on machine learning algorithms evaluate websites as Excellent, Informative or Not Useful. Results of this approach are promising, but inconclusive as the dataset of websites for training and testing was not sufficiently large for any real conclusions to be made. Keywords: health informatics, website evaluation, machine learning Introduction
Over the last few years there has been an increased emphasis on Web-based patient or consumer education systems with respect to health and medicine on the assumption that, through the Web, patients can become knowledgeable about their health conditions and be more involved in the management of their own health. However, while the large volume of health information resources available on the Web has the potential to improve the quality of health, it is increasingly difficult to identify the accuracy and appropriateness of these resources for the consumer.
The successful development of instruments to evaluate the health information on the Web is not an easy task as there is no “gold standard” to appraise the content of the website and there is controversy around the definition of quality controlling characteristics of a website. One important question to be
ARD Prasad & Devika P. Madalli (Eds.): ICSD-2007, pp. 529-538, 2007
answered is, “Which characteristics of a website are “valid” quality criteria to discriminate or predict a “good” health website?” A valid quality criterion should be a single feature or a collection of features that predicts effective health communication in terms of improving knowledge or changing health behavior, and which is associated with a measurable positive effect on health outcomes.
The primary objective of our research is to develop a machine learning methodology that systematically evaluates websites containing educational information about Inflammatory Bowel Disease (IBD). A small set of websites, manually evaluated by experts in the field, is used as the data set. A top-down induction decision tree algorithm is applied on these websites to generate standards for Excellent, Informative and Not Useful websites. These standards are used further to rate the quality of new websites under evaluation.
Section 2 of this paper is a summary of related research. Section 3 describes the websites evaluated and the methodology followed by medical experts to evaluate these websites. Section 4 presents our proposed system and the methodology to develop and evaluate the system. Section 5 presents the results and Section 6 summarizes the paper and suggests areas for future research.
Related Research
An extensive systematic review (Eysenback, et al., 2002) of the literature on consumer health information on the Web concludes that the validity of health information available on the Web is highly variable across different diseases and in many cases is potentially misleading and/or harmful. There are a large number of incompletely developed instruments to evaluate such information and many of these instruments are flawed or have not been properly evaluated (Gagliardi and Jadad, 2002). They do not have any discriminating power and can mislead the consumers seeking health care information. It is unclear that they measure what they claim to measure or whether they lead to more good than harm.
After extensive review, Eysenbach, et al. (2002) identified three criteria whose presence can statistically be used as valid quality criteria for evaluating a website. These are the disclosure of ownership, the presence of copyright notice and the disclosure of advertisements’ purpose, if any. If any of these criteria are present, then statistically they indicate that the information on the website is of some quality. However, these criteria are often absent and, even if present, cannot be used to rate or rank the websites for the user, i.e., indicate which website the consumer should look at first.
Evaluation of Health Information on the Web 531
The ultimate purpose of a quality medical website is to help consumers better manage their health by providing quality up-to-date information about the disease. Keeping this in mind, two medical experts (interns in Gastroenterology), after extensive literature review and discussion with health care professionals in the area of Gastroenterology identified the 11 domains of knowledge that should be present in a quality web site discussing IBD. These include such domains as general disease information, symptoms, diagnosis, etc.
Evaluating the 11 knowledge domains, the experts found that the “Medical Treatment” section is information rich with name, composition, and synonym of all available medications along with information on the indications and contra-indications for use of medication, data on efficacy and side effects. Therefore, in this study, the experts evaluated only the “Medical Treatment” section of the IBD websites as it is an ideal component encasing the total complexity of the generalized problem – medical website evaluation.
3.1 Generating the Data Set The query, [“Crohn’s disease” OR “ulcerative colitis” OR IBD], was presented to Google on two occasions with a time interval of 5-6 months. The two medical experts examined the first 50 resulting websites from each Google search. The websites needed to meet the following inclusion criteria: 1) provide educational information on IBD and 2) be written in English. There were two exclusion criteria: 1) if the website was primarily a portal website leading to another site and 2) if the website focused primarily on other gastroenterology problems such as irritable bowel syndrome. Of the 50 websites from each search, 32 and 29 respectively met the inclusion criteria. There were 18 sites found in both searches resulting in a final list of 43 websites.
After an extensive literature review, the experts identified five characteristics that indicate the quality of health websites. They are goodness of the available information, user friendliness of the website design, average reading level of the website, integrity of website and details of recent updates. Based on these characteristics, five attributes were designed to evaluate the websites and applied to the “Medical Treatment” sections of each website. These were extensive evaluation instruments and can be obtained by contacting the authors.
Evaluating the 43 websites, 6 web sites were rated as Excellent, 8 as Informative and the remainder as Not Useful. In general there was poor correlation between the ranking within the Google search and ranking according to the experts. The 6 highest ranked websites did not necessarily appear high in the Google search results, ranging from 1st to 30th in the first
search and 3rd to 34th in the second. Inter-rater reliability between the two experts was high at 84.4% (first Google search) and 83% (second Google search).
Methodology
Of the 43 websites evaluated by the experts, only 36 were still available on the Web at the time of this research. These 36 had been rated by the experts as 6 Excellent, 8 Informative and 22 Not Useful. In order to provide a balanced data set for the purpose of machine learning for classification, the 36 websites were reduced to 18 websites, 6 in each category of Excellent, Informative and Not Useful. Each website was crawled to a maximum depth of seven from the target URL to gather the web pages that would be used in the classification of each website.
Three-fold cross-validation was used to determine a training set and a test set for the generation of the decision tree and evaluation of websites. Thus, 3 iterations were performed, each with 12 websites in the training set and 6 websites in the test set.
4.1 Selection of Attributes for Decision Tree Only those web pages examined by the experts were used to develop the attributes for the training set,. From those pages of the 18 websites, a set of 10 attributes (Table 1) were selected upon which a top-down decision tree was induced. The first 4 of these attributes are based on an IBD vocabulary of 49 terms supplied by the experts, while 6 attributes were selected from the literature on evaluation of health websites (Eysenbach, 2002; Eysenbach, et al., 2002).
In order to calculate values for each website for the first 4 attributes of Table 1, the following process was followed:
1. Calculate the term-frequency inverse document frequency weight
(tf.idf) of each term. The collection of web pages at each website was treated as a single “document”, giving us 18 “documents” in the dataset for this purpose.
2. Calculate a Content Score for each website by summing the weights
of all the IBD vocabulary terms at each website
3. Rank the websites by the Content Scores 4. Calculate the average deviation of these ranks from the expected set
5. Adopt a trial and error strategy to minimize the average deviation by
identifying the high frequency IBD terms across the 12 websites in the training set and eliminating those terms with those frequencies, and evaluating the average deviation after each step
Evaluation of Health Information on the Web 533
It was found that the smallest average deviation was found when terms with frequencies greater than 100 were eliminated.
4.2 Induction of Decision Tree Given the set of attributes in Table 1, and values for each website, and the known class of each website, a decision tree can be induced that can classify new websites. Quality Criteria Significance Table 1. Attribute set for generation of decision tree.
Twenty-two attribute selection measures were evaluated using the induction decision tree algorithm as applied on the then attributes. For each measure, three decision trees were generated; trees with no pruning, trees with confidence pruning and trees with pessimistic pruning. The resulting classifications were evaluated against the known classification and the attribute selection measure and pruning algorithm with the smallest error rate was chosen for the tree induction. In this case, the Information Gain measure with pessimistic pruning was chosen as it had the lowest error rate. In fact, its error rate was 0.
4.3 Evaluating a Candidate Website A crawl depth of 7 returns hundreds if not thousands of web pages, but not all are useful for our evaluation. For instance one URL had 1478 web pages within depth 7, of which 670 had IBD medication related vocabulary but only 28 pages discussed the disease, IBD. As the same medication is used for different diseases and the same side-effects, indication and contra-indication can be generated by more than one medicine our evaluation procedure should be based on these 28 IBD web pages. Therefore, it is necessary to filter the web pages at a site so that only pertinent web pages are part of the evaluation. This is achieved in our system through generating “Association Hyperedges” of the 49 IBD terms using an enhanced version of the Association Mining algorithm (Agrawal, 1994).
An association hyperedge is a collection of medical terms pertinent to a disease having a higher probability of appearing together than they would for another disease. To generate the association hyperedge, each web page in the web site is considered as a transaction T. For example, www.ccfa.org has 232 web pages within depth 7, so we can say that ccfa.org has 232 transactions. From the group of 232 transactions, combinations of the 49 supplied IBD medical terms are discovered (i.e. “association hyperedges”or “hyperedges”) using the Association Mining principle.
These Association Hyperedges are assigned support values. Let T be the set of all transactions under consideration, The support of an item set S is the percentage of those transactions in T which contain S. If U is the set of all transactions that contain all items in S, then support(S) = (|U| / |T|) *100 where |U| and |T| are the number of elements in U and T, respectively.
Given an item set with enough “support”, rules are generated using the Association Mining algorithm. For example, for the item set {mp, azathioprine, corticosteroids} the following rules are generated:
where mp, azathioprine -> corticosteroids means the probability of the item corticosteroids coming together with mp and azathioprine.
The confidence of a rule “a, b -> c” is the support of the set of all items that appear in the rule divided, by the support of the antecedent of the rule, i.e., confidence(R) = (support ({a, b, c}) / support ({a, b})) *100.
Although hyperedges selected using support and confidence may be “good” hyperedges, they are not always “interesting”. For instance, in a medical
Evaluation of Health Information on the Web 535
database, the rule “diabetes -> blood-glucose” may be true with a confidence of 100%. Hence it is a perfect rule, so a hyperedge {diabetes, blood-glucose} never fails. However, this transaction has not revealed any hidden correlations within the dataset.
Potentially interesting rules differ significantly in their confidence from the confidence of rules with the same consequent, but a simpler antecedent. Adding an item to the antecedent is informative only if it significantly changes the confidence of the rule. Otherwise the simpler rule suffices. To keep track of this, we use two additional evaluation measures - the prior confidence and the posterior confidence. We can call the confidence of a rule with empty antecedent the prior confidence, since it is the confidence that the item in the consequent of the rule will be present in an item set prior to any information about other items that are present. The confidence of a rule with non-empty antecedent (and the same consequent) we call the posterior confidence, since it is the confidence that the item in the consequent of the rule will be present after it becomes known that the items in the antecedent of the rule are present. The Principle of Entropy is used to calculate the prior confidence and the posterior confidence and the Information Gain of adding an antecedent can now be calculated. Information Gain is included in the hyperedge algorithm, along with the support and confidence, to generate all possible association hyperedges from the selected group of transactions.
The confidence of each generated rule is computed and the average confidence is measured. If the resulting average confidence is greater than a minimal confidence and if the difference between the prior confidence and the posterior confidence is greater than a user defined baseline value, then the hyperedge from which the rules were generated is qualified by the inclusion criteria and only those web pages with all the medical terms of at least a single qualified hyperedge are considered for the rating of the website.
4.3.1 Optimal Values of Support, Confidence and Information Gain Data filtering is now controlled by the following parameters: percentage support, percentage confidence and percentage value of Information Gain
A small change in any of the above percentages creates large differences in the number of generated hyperedges and a subsequent loss of information. Optimal values of these parameters can be determined using Receiver Operating Characteristics (ROC) analysis on already evaluated websites and used to generate the hyperedges for a new website under evaluation (Kawahara and Kawano, 2001).
The ROC curve is a graph connecting the True Positive Rate (Y-axis) and the False Positive Rate (X-axis) of a resulting classification. Using the already evaluated 12 websites , ROC curves are generated for %confidence varying
from 60 to 100 (with a uniform interval of 5) and %support varying from 0 to 50 (with a uniform interval of 0.2) with fixed value of information gain equal to 1.
Figure 1. Area under the ROC curve
An ROC curve is a two-dimensional depiction of classifier performance. To compare classifiers we want to reduce ROC performance to a single scalar value representing the measure of performance. A common method is to calculate the area under the ROC curve. From our experiments, we can conclude that support of 1.2 % is optimum for a classifier with confidence of 100% and IG of 1, and these values are used to generate the association hyperedges and subsequent dimensionality reduction.
4.3.2 Scoring Algorithm Association hyperedges are used to reduce the number of web pages at each test set website that must be evaluated. Only those web pages which have all the IBD terms from at least one hyperedge are used to generate the values of attributues discussed in Table 1. These data for each website are used to traverse the decision tree that was generated from the training set and the website under evaluation is classified as Excellent, Informative or Not Useful. In addition, the content score for each website is generated by summing the term weights of the IBD terms in the pages at that website.
Table 2 contains the results of the website evaluation after three-fold cross-validation was applied to the balanced dataset of 18 websites. The 18 websites are listed in rank order according to the experts’ ratings. Note that there are ties in rank in both the expert’s ratings and in the system’s rating.
Evaluating the results of 3-fold cross validation (Table 2), inter-rater agreement between the medical expert and the proposed system is 98%. Only
Evaluation of Health Information on the Web 537
2 websites were misclassified (shown in bold), for a classification accuracy of 89%.
Summary and Discussion
The World Wide Web and the rapid development of other information technologies are creating new opportunities to improve decisions and communications in health care, but can also generate unprecedented problems by disseminating inaccurate information. Judging whether the health information available on the Web is appropriate and credible for the consumers presents greater challenges than just searching for and finding information.
Experts System Class Rank Class Rank Table 2. A comparison of the classification and ranking by the experts and the designed system using 3 fold cross validation. Note that Class E is Excellent, IN is Informative and NU is Not Useful.
In this research we have developed a system for evaluating health information on the Web. To achieve this goal, a clear, simple set of consensus criteria that can indicate the quality of health information on the Web has been identified and assessed using the statistics from previous research by experts in this area. Statistical validity of these quality criteria has been analyzed and a system that integrates these criteria has been developed with the help of machine learning and data mining techniques.
The preliminary results of this approach are promising, but inconclusive as the dataset of websites for training and testing as determined by experts was not sufficiently large for any real conclusions to be made. Further research will include development of a sufficiently large dataset evaluated by experts, generalization of the methodology across multiple diseases and the identification of appropriate medical terminology for each disease based on standard vocabularies such as found in the Unified Medical Language System.
References
[1] Agrawal, Srikant. (1994). Fst algorithms for mining association rules
in large databases. Proceedings of the 20th International Conference on Very Large Data Bases. 487-499.
[2] Eysenbach, G. (2002). Infodemiology: The Edpidemiology of
(Mis)information. American Journal of Medicine. Dec. 2002; 113: 763-765.
[3] Eysenbach, G. Powell, J., Kuss, O. and E.R. Sa. (2002) Empirical
study on accessing the quality of health information for consumers on World Wide Web – A systematic review, JAMA, May 22/29 2002; 287 2691- 2698.
[4] Gagliardi, Anna and Alejandro R. Jadad. (2002). Examination of
instruments used to rate quality of health information on the internet: Chronicle of a voyage with an unclear destination. BMJ, March 2002, 324: 569-573.
Kawahara, Minoru and Hiroyuki Kawano. (2001). Mining Association Algorithm with Improved Threshold based on ROC Analysis, Proceedings of the 34th Hawaii International Conference on System Science, 2001,703 -706.
DAtI ANAGRAFICI IStRUzIoNE E FoRMAzIoNE Seminario from A to Web Macromedia (Roma)Master in comunicazione visiva e grafica pubblicitaria (c/o Centro Studi Comunicazione Enrico Cogno ed Associati)Liceo artistico (c/o Istituto Sant’Orsola di Roma) ESPERIENzE PRoFESSIoNALI Freelance per Gag (Filmaster Group) / Studio Jumblies / Peja Design Ideazione, progettazione grafica di: Asiatica
Prescribing Tai Chi for Fibromyalgia — Are We There Yet? Gloria Y. Yeh, M.D., M.P.H., Ted J. Kaptchuk, and Robert H. Shmerling, M.D. Fibromyalgia is a common and poorly under-It is no wonder, then, that many people with stood pain disorder that afflicts an estimated fibromyalgia seek out less conventional (and less 200 million or more people worldwide.1 The lack evidence-based) treatments
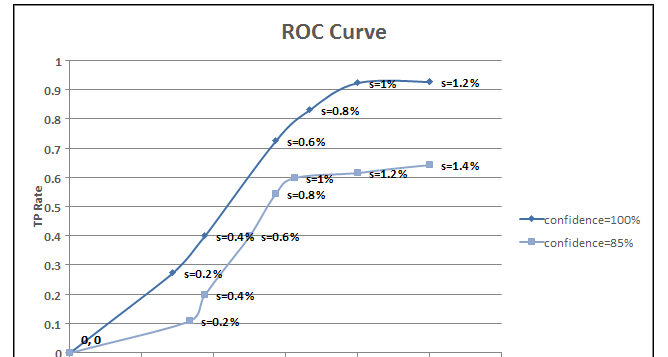
 from 60 to 100 (with a uniform interval of 5) and %support varying from 0 to 50 (with a uniform interval of 0.2) with fixed value of information gain equal to 1.
Figure 1. Area under the ROC curve
from 60 to 100 (with a uniform interval of 5) and %support varying from 0 to 50 (with a uniform interval of 0.2) with fixed value of information gain equal to 1.
Figure 1. Area under the ROC curve