Le sildénafil présent dans Kamagra exerce une inhibition réversible de la PDE5, modulant la cascade GMPc et favorisant une vasodilatation localisée. L’absorption digestive varie selon la forme utilisée, comprimés classiques ou gels oraux. La distribution tissulaire est large et la liaison protéique élevée, avoisinant 96 %. La métabolisation hépatique génère un métabolite actif contribuant à l’effet pharmacologique global. La demi-vie reste courte, avec disparition plasmatique en quelques heures. Les interactions significatives concernent surtout les nitrés organiques et inhibiteurs puissants du CYP3A4. Dans les publications techniques, kamagra en ligne est souvent cité dans le cadre d’analyses comparatives portant sur les différences de formulations et de cinétique d’absorption.
Powerpoint presentation
• Example of intelligent system: OCR• k-Nearest Neighbor Classifier• Generative model• Maximum likelihood• Naïve Bayes model• Gaussian model
– Input: scanned images, photos, vdo images– Output: text file
– Electronic stylus e.g. PDA– Online handwritten recognition
– Image enhancement, denoise, deskew, . – Binarization
• Layout analysis and character segmentation• Character recognition• Spell correction
• Preprocessing uses image processing tech. • Layout analysis uses rule-based + some stats. • Character recognition
– Classifier (trained from training corpus)– Look-up table: no class -> ascii or UTF code
• Spell correction uses dictionary + some stats
– All separated character: Neural Network, SVM– Few touched characters: Class of touched char– Some broken characters (อำำ): Class of sub-char– Rule-based segmentation
– Several touched chars (e.g. arab, urdu): 2D-
• Normalize character image (reduce variation, get
• Contain more information• Cannot reliably detected
– Low-level features: pixels color, edge
• Single feature is not meaningful• Can be easily detected• Can be improved: PCA, LDA, NLDA, .
• Design class• Build a feature extractor, ex: vector of pixels color• Construct a training corpus
– 1 example = 1 vector and 1 class– Very large number of examples– Cover all conditions: dpi, fonts, font sizes, style
(e.g. slant, bold), writing styles, pen styles,
• Collect sample• Segment from forms or manual segmentation
• Print different fonts, font sizes, . • Scan, scan of copy, .
• SNNS or fann for Neural Network• libsvm or svmlight for SVM• weka
– Format of training corpus– Parameters and their values– How to use it in your code
• Biological inspired multi-class classifier• Set of nodes with oriented connections
• Try MLP with 1 hidden layer first• 1 parameter = number of hidden nodes• Training with Gradient descent• 1 training parameter = learning rates
• Linear classifier using kernel trick trained to tradeoff
• output is linear combination of input features• y = sign(wTx)• Use multiple linear classifier for multi-class
• Replace all dot product with a kernel function• K(x1,x2) = <g(x1); g(x2)> with some unknown
– Small C = generalization is more important than error – Large C = error is more important
– gamma = inverse of area of influence around
– C = trade off parameter between error on training
– Rough classification: upper vowel, mid-level
– Rough classification: upper vowel, mid-level
– Fine classification: กถภ, ปฝฟ, . – Finer classification
• Prototype-based classifier, template-based classifier• Distance function• Useful when
– We have very limited number of training examples,
– We have large number of training examples, just to
– When n→ ∞, 1NN error < 2 bayes error
If we do know P(Class |x),.,P(Class |x), then the Bayes
produces the minimum possible expected error = Bayes error
N number of examples of class y in training set
• Put the input object into the same class as most of
– Compute distance between input and each training
– Sort in increasing order– Count number of instances from each class amongst
• There is no k which is always optimal
• Norm-p distance ∣x−y∣p=∑xi−yip1/p
distx , y=x−y T −1 x− y
dist x , y=K x , xK y , y −2K x , y
• Solving classification problem = build P(class|input)• P(class |input) = P(input|class ) P(class ) / P(input)
• P(input) = Σ P(input|class ) P(class )
• P(class ) = percentage of examples from class i in the
• Solving classification problem = build P(input|class )i• P(input|class ) = likelihood of class
• P(class |input) = posterior probability of class
• To build P(input|class ) we usually made an
– How the data from the class i is distributed, e.g.
– How each input i.e. document is represented?– What is the likelihood model for these data?
• Spam/not-spam• Document = set of words• Preprocessing
– word segmentation– remove stop-words– stemming– word selection
• Naïve Bayes assumption: all words are
• Same hypothesis for all classes• How to compute P(w |Spam), why?
• What is the process of building Naïve Bayes
• x ,.,x are i.i.d. according to P(x|θ) where θ is the
• Q: What is the proper value for θ?• A: The value which gives maximum P(x ,.,x |θ)
• Q: We know P(x|θ), how to compute P(x ,.,x |θ)?
• Q: How to find the maximum value?• Q: How to get ride of the product?
– Q: What this means? What is P(w|Spam)– word “viagra” – {T, F, F, T, T, T, F, T, F, T }– Find proper parameter for P(w|Spam)
– {H, T, H, H, T, H, H, H, T, H}– Q: What is the parameter of Binomial
• Sometimes, we have prior knowledge about the model,
• We search for maximum P(θ|x ,.,x ) instead
• Q: How to compute P(θ|x ,.,x ) from P(θ) and P(x|θ)?
• Exercise: coin-toss problem θ is distributed as Gaussian
with mean 5/10 and standard deviation 1/10
– Q: What is Gaussian model?– Q: What is the proper value for θ?
• ML is good when we have large enough data• MAP is prefered when we have small data• Prior can be estimated from data too
SUMMARY OF PRODUCT CHARACTERISTICS NAME OF THE MEDICINAL PRODUCT Axura 10 mg film-coated tablets. 2. QUALITATIVE AND QUANTITATIVE COMPOSITION Each tablet contains 10 mg of memantine hydrochloride (equivalent to 8.31 mg memantine). For excipients, see section 6.1. 3. PHARMACEUTICAL FORM Film-coated tablets. The film-coated tablets are white to off-white, centrally



 • Preprocessing uses image processing tech.
• Preprocessing uses image processing tech.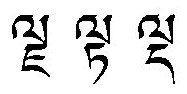 – All separated character: Neural Network, SVM– Few touched characters: Class of touched char– Some broken characters (อำำ): Class of sub-char– Rule-based segmentation
– Several touched chars (e.g. arab, urdu): 2D-
• Normalize character image (reduce variation, get
• Contain more information• Cannot reliably detected
– Low-level features: pixels color, edge
• Single feature is not meaningful• Can be easily detected• Can be improved: PCA, LDA, NLDA, .
– All separated character: Neural Network, SVM– Few touched characters: Class of touched char– Some broken characters (อำำ): Class of sub-char– Rule-based segmentation
– Several touched chars (e.g. arab, urdu): 2D-
• Normalize character image (reduce variation, get
• Contain more information• Cannot reliably detected
– Low-level features: pixels color, edge
• Single feature is not meaningful• Can be easily detected• Can be improved: PCA, LDA, NLDA, .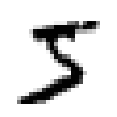
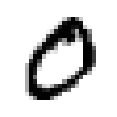
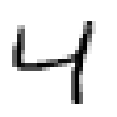
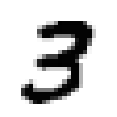
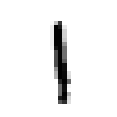 – Rough classification: upper vowel, mid-level
– Rough classification: upper vowel, mid-level
– Fine classification: กถภ, ปฝฟ, .
– Rough classification: upper vowel, mid-level
– Rough classification: upper vowel, mid-level
– Fine classification: กถภ, ปฝฟ, .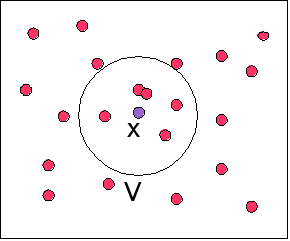 N number of examples of class y in training set
• Put the input object into the same class as most of
– Compute distance between input and each training
– Sort in increasing order– Count number of instances from each class amongst
• There is no k which is always optimal
• Norm-p distance ∣x−y∣p=∑xi−yip1/p
distx , y=x−y T −1 x− y
dist x , y=K x , xK y , y −2K x , y
• Solving classification problem = build P(class|input)• P(class |input) = P(input|class ) P(class ) / P(input)
• P(input) = Σ P(input|class ) P(class )
• P(class ) = percentage of examples from class i in the
• Solving classification problem = build P(input|class )i• P(input|class ) = likelihood of class
• P(class |input) = posterior probability of class
• To build P(input|class ) we usually made an
– How the data from the class i is distributed, e.g.
– How each input i.e. document is represented?– What is the likelihood model for these data?
• Spam/not-spam• Document = set of words• Preprocessing
– word segmentation– remove stop-words– stemming– word selection
• Naïve Bayes assumption: all words are
• Same hypothesis for all classes• How to compute P(w |Spam), why?
• What is the process of building Naïve Bayes
• x ,.,x are i.i.d. according to P(x|θ) where θ is the
• Q: What is the proper value for θ?• A: The value which gives maximum P(x ,.,x |θ)
• Q: We know P(x|θ), how to compute P(x ,.,x |θ)?
• Q: How to find the maximum value?• Q: How to get ride of the product?
– Q: What this means? What is P(w|Spam)– word “viagra” – {T, F, F, T, T, T, F, T, F, T }– Find proper parameter for P(w|Spam)
– {H, T, H, H, T, H, H, H, T, H}– Q: What is the parameter of Binomial
• Sometimes, we have prior knowledge about the model,
• We search for maximum P(θ|x ,.,x ) instead
• Q: How to compute P(θ|x ,.,x ) from P(θ) and P(x|θ)?
• Exercise: coin-toss problem θ is distributed as Gaussian
with mean 5/10 and standard deviation 1/10
– Q: What is Gaussian model?– Q: What is the proper value for θ?
• ML is good when we have large enough data• MAP is prefered when we have small data• Prior can be estimated from data too
N number of examples of class y in training set
• Put the input object into the same class as most of
– Compute distance between input and each training
– Sort in increasing order– Count number of instances from each class amongst
• There is no k which is always optimal
• Norm-p distance ∣x−y∣p=∑xi−yip1/p
distx , y=x−y T −1 x− y
dist x , y=K x , xK y , y −2K x , y
• Solving classification problem = build P(class|input)• P(class |input) = P(input|class ) P(class ) / P(input)
• P(input) = Σ P(input|class ) P(class )
• P(class ) = percentage of examples from class i in the
• Solving classification problem = build P(input|class )i• P(input|class ) = likelihood of class
• P(class |input) = posterior probability of class
• To build P(input|class ) we usually made an
– How the data from the class i is distributed, e.g.
– How each input i.e. document is represented?– What is the likelihood model for these data?
• Spam/not-spam• Document = set of words• Preprocessing
– word segmentation– remove stop-words– stemming– word selection
• Naïve Bayes assumption: all words are
• Same hypothesis for all classes• How to compute P(w |Spam), why?
• What is the process of building Naïve Bayes
• x ,.,x are i.i.d. according to P(x|θ) where θ is the
• Q: What is the proper value for θ?• A: The value which gives maximum P(x ,.,x |θ)
• Q: We know P(x|θ), how to compute P(x ,.,x |θ)?
• Q: How to find the maximum value?• Q: How to get ride of the product?
– Q: What this means? What is P(w|Spam)– word “viagra” – {T, F, F, T, T, T, F, T, F, T }– Find proper parameter for P(w|Spam)
– {H, T, H, H, T, H, H, H, T, H}– Q: What is the parameter of Binomial
• Sometimes, we have prior knowledge about the model,
• We search for maximum P(θ|x ,.,x ) instead
• Q: How to compute P(θ|x ,.,x ) from P(θ) and P(x|θ)?
• Exercise: coin-toss problem θ is distributed as Gaussian
with mean 5/10 and standard deviation 1/10
– Q: What is Gaussian model?– Q: What is the proper value for θ?
• ML is good when we have large enough data• MAP is prefered when we have small data• Prior can be estimated from data too